Speaker Diarisation and Speech Recognition
This post discusses Speaker Diarisation and Speech Recognition in simple terms using accessible language for all.
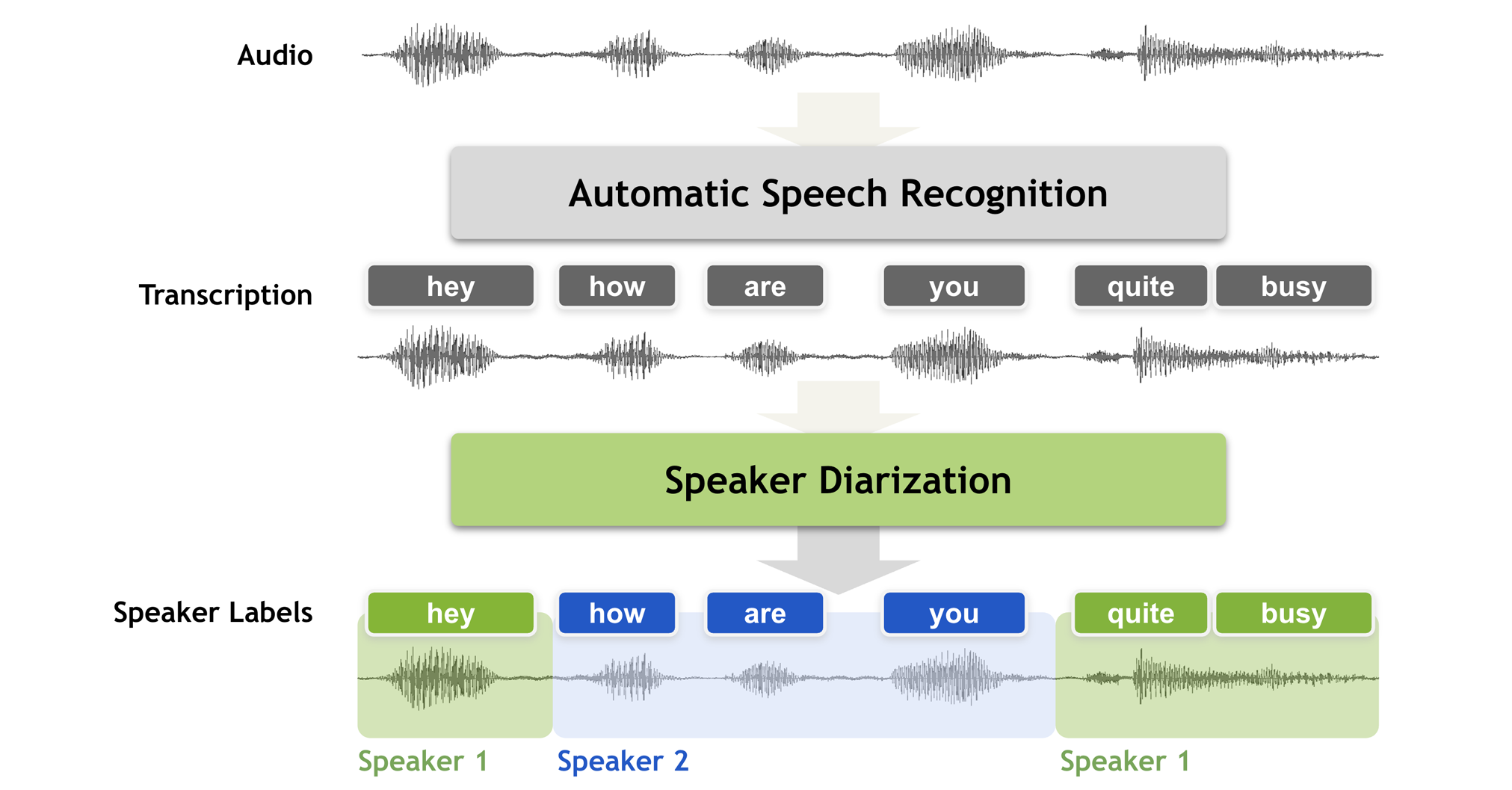
A Simple Guide to Speaker Diarisation and Speech Recognition
Speaker Diarisation
What is Speaker Diarisation?
Speaker diarisation is the process of identifying and segmenting different speakers in an audio recording. The primary goal is to answer the question: “Who spoke when?” This is especially important in environments with multiple speakers, such as meetings, interviews, and legal proceedings.
Example
In the context of police investigations, speaker diarisation can be used to analyse conversations recorded on body-worn video cameras. For instance, when officers interact with witnesses or suspects, it’s crucial to distinguish between different voices. By identifying who is speaking at any given moment, investigators can better understand the context of the conversation and gather more accurate information.
How is Speaker Diarisation Performed?
Speaker diarisation involves several steps:
Step 1: Audio Preprocessing
The audio recording is cleaned up to enhance clarity. This may include:
- Noise Reduction: Removing background noise to focus on the voices.
- Segmentation: Dividing the audio into smaller segments based on pauses or changes in the speaker.
Step 2: Feature Extraction
Key features from the audio are extracted to distinguish between different speakers. These features capture the characteristics of the audio signal and help in identifying unique voice patterns.
Step 3: Clustering
The extracted features are grouped together using clustering algorithms, which helps identify segments where the same speaker is talking.
Step 4: Speaker Labelling
Once segments are clustered, each segment is labeled with the corresponding speaker’s identity. If the speakers are known, they can be matched to previously recorded voice profiles.
Speaker Diarisation Limitations
- Overlapping Speech: When multiple speakers talk at the same time, it can be difficult to accurately identify who is speaking.
- Quality of Audio: Poor audio quality can hinder the diarisation process, leading to misidentification.
Speech Recognition
What is Speech Recognition?
Speech recognition is the technology that enables computers to understand and interpret spoken language. The goal is to convert spoken words into written text, allowing for easier analysis and documentation.
How Does Speech Recognition Work?
Speech recognition involves several key steps:
Step 1: Audio Input
The system takes in audio input from various sources, such as microphones or audio recordings. In the context of body-worn video cameras, this would be the audio captured during an interaction.
Step 2: Preprocessing
Similar to diarisation, the audio is cleaned and prepared for analysis. This includes:
- Noise Reduction: Enhancing the clarity of speech by removing background sounds.
- Segmentation: Breaking the audio into manageable chunks, such as words or phrases.
Step 3: Feature Extraction
Features are extracted from the audio to analyse the speech patterns. This includes visualising the frequencies in the audio signal over time to identify distinct sounds.
Step 4: Decoding
The extracted features are compared against known patterns in a speech database using machine learning algorithms. This step involves:
- Hidden Markov Models (HMMs): A statistical model that predicts the likelihood of a sequence of sounds based on past observations.
- Deep Learning: Neural networks can be trained to recognise complex patterns in speech, improving accuracy.
Step 5: Output Generation
The recognised words are then converted into written text. This text can be further analysed or stored for record-keeping.
Speech Recognition Limitations
- Accents and Dialects: Variability in accents or dialects can affect the accuracy of speech recognition systems.
- Background Noise: High levels of background noise can interfere with the system’s ability to understand spoken words.
Summary Example
Police body-worn video cameras capture crucial interactions between officers, suspects, and witnesses. By applying speaker diarisation and speech recognition technologies to the audio captured in these videos, law enforcement can:
- Create Accurate Transcripts: Convert spoken dialogue into text for better record-keeping and analysis.
- Identify Speakers: Differentiate between officers, suspects, and witnesses, improving the clarity of investigations.
- Analyse Interactions: Examine the context and content of conversations to gather evidence or assess the conduct of officers during incidents.
By using these technologies, police departments can enhance their investigative processes and ensure accurate reporting of events, ultimately contributing to justice and accountability.
Key Takeaways
- Speaker Diarisation identifies “who spoke when” in an audio recording, helping differentiate between multiple speakers.
- Speech Recognition converts spoken language into written text, enabling analysis and documentation of verbal interactions.
- Limitations include challenges with overlapping speech, accents, background noise, and poor audio quality, which can affect the accuracy of both diarisation and recognition.
Glossary of Key Terms
- Speaker Diarisation: The process of identifying and segmenting different speakers in an audio recording, determining “who spoke when.”
- Speech Recognition: The technology used to convert spoken words into written text.
- Audio Preprocessing: Techniques such as noise reduction and segmentation to clean and prepare audio data for further analysis.
- Feature Extraction: The process of identifying key patterns in the audio data (such as voice tone or frequency) that can distinguish between speakers.
- Clustering: A method of grouping similar data points (e.g., audio segments) to identify distinct speakers in diarisation.